Fatigue Analysis Rainflow Cycle Counting
Rainflow cycle counting · custom software build
At High Creek Software we have been working on a purpose specific tool to extract cycles out of an inline inspection dataset. Our hope is to provide an accurate and fast process for extracting cycle data to be used in fatigue life analysis.
To get started, this is still a work in progress, but we feel that we’ve made good enough progress to start talking about it. Right now, we have a project based UI where you can:
Apr. 15, 2023 1265 words golang · fyne · fatigue-analysis ·
Rainflow cycle counting · custom software build
At High Creek Software we have been working on a purpose specific tool to extract cycles out of an inline inspection dataset. Our hope is to provide an accurate and fast process for extracting cycle data to be used in fatigue life analysis.
To get started, this is still a work in progress, but we feel that we’ve made good enough progress to start talking about it. Right now, we have a project based UI where you can:
- Import a new dataset with a unique name
- View previously imported datasets
- See metadata for your datasets
- Import duration
- Cycle extraction duration
- Data points in the dataset
- Reversal count
- Cycle count
- Scrollable charts for
- All data (raw dataset)
- Found reversals
- Cycles list
- Range
- Mean
- Count
- Start index
- End index
- Multiple binned cycle counts
Main Goals
At the outset of this project we have had 4 main goals for the resulting software:
- Accurate
- Lossless
- Efficient
- Quick
We are using these 4 goals to dictate the design of the software. If our main goal was to just be as fast as possible, it could be done, but we’d be leaving some other important features behind. Because of this, you’ll notice that quickness is the fourth goal on our list of goals.
Accurate
Building an piece of software to support an engineering discipline requires utmost accuracy. To do this, we’re baking tests into the development process. We’re starting with some small known datasets, and writing tests that verify the extraction process. This will provide a reference point to verify as changes are introduced into the import, counting, and binning pipelines.
Lossless - Data Preservation
As mentioned above, if speed was our only goal, we could make this fast. But it isn’t, we want to display the data that is passed through onto each step. The bulk of the cycle counting step is to identify reversals in the data, and then counting the resultant cycles. However, including hystersis filtering will help take the noise out of the data, and we want to show what was filtered there as well.
To do this, all of the source data points are added into a project database (just a sqlite3 file). There, each data point is flagged as why it was used in the final cycle counts along the processing steps. With a sqlite3 databse at the core of the data storage, queries can be built to really give visibility in the resultant cycle counts.
Efficient
We wanted this to run on your basic desktop workstation or laptop. Our workstations start out at 32GiB of memory, we do this because we know what our workloads look like. But what about the case where there are more modest specs on the machine running the softwrae, we feel that those should be supported as well. How do we do this? We stream all of the data that we work with. Our imports are streamed into the database (where a min and max is calculated for the dataset). When we start counting cycles, that is all streamed from the sqlite3 database mentioned above. The result, a lossless data processing pipeline of tens of milliions of data points, using not much more than a couple of hundred MiBs of memory!
We use green threads by way of goroutines (oops we just gave away the secret of our stack, yep we’re using go for the desktop via fyne). This lets us keep our jobs working in the background and your UI responsive to do all of the other concurrent work we talked about before.
Quick
We’ve already covered our prvious goals, but, we still want the data processing to be quick enough that it will be used. The challenge though? It is really hard to say how quick our solution really is. How does it stack up to other projects that exist out there? I’m not sure, and our previous goals keep me from wanting to make a direct comparison.
But this is what I can say, I build in a random dataset generator to the tool, then I produced a handful of datasets to run through the import and cycle counting stages of the pipeline. And I’m quite impressed with what we have.
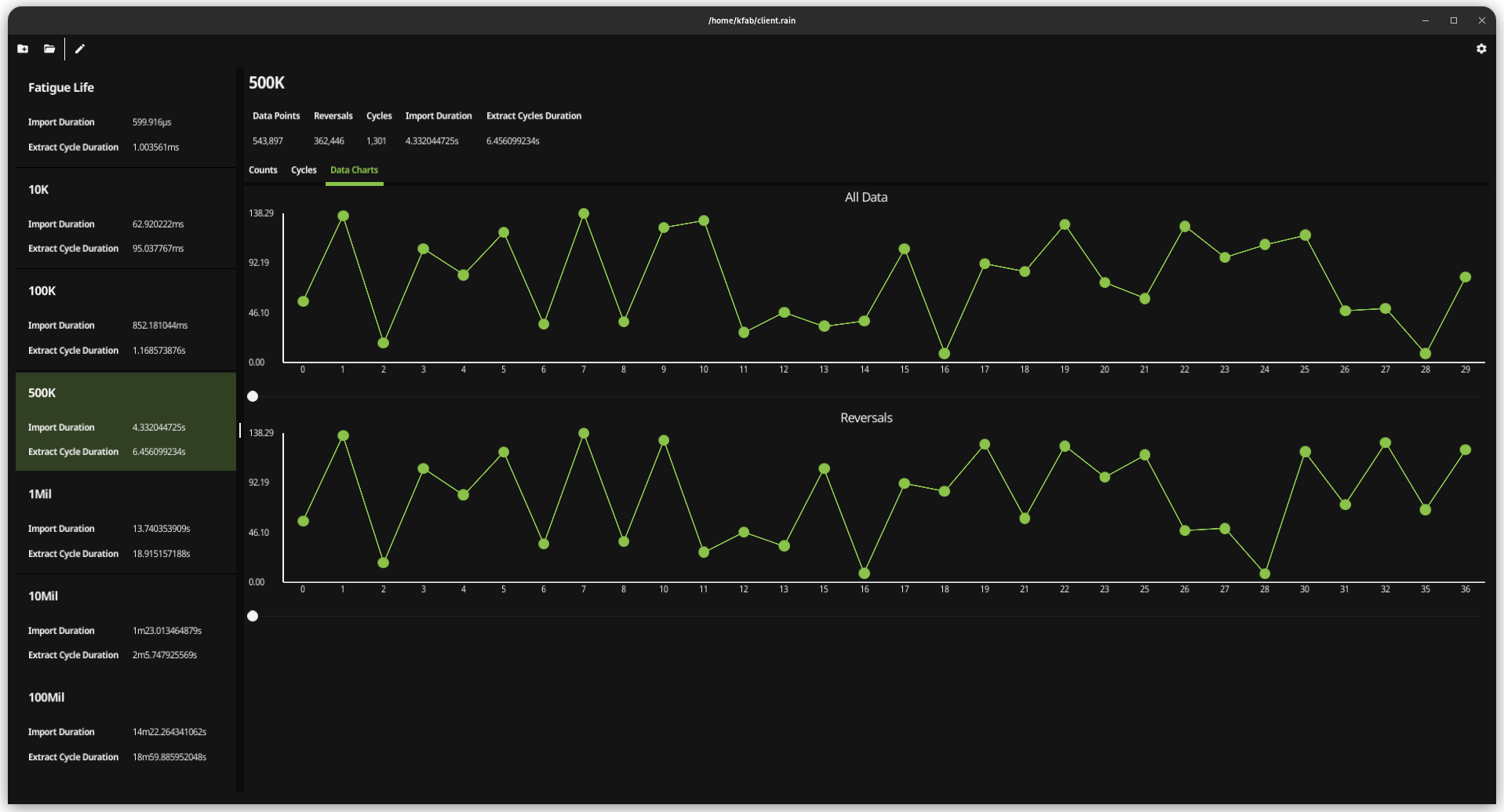
| Dataset Size | Import Duration | Extract Cycle Duration |
| 10K | 63 ms | 95 ms |
| 100K | 852 ms | 1.2 s |
| 500K | 4.3 s | 6.45 s |
| 1Mil | 13.7 s | 18.9 s |
| 10Mil | 1 m 23 s | 2 m 5 s |
| 100Mil | 14 m 22 s | 18 m 59 s |
As mentioned above, there might be faster pipelines out there, but I sure feel that at around 30 minutes to import and count the cycles in a 100 million point dataset, that is still quick enough to run the data through that you’d need to (don’t forget that you’re still responsive to compute other types of workloads while this is going on).
Guiding Principles
Along with our 4 main goals, we also have some guiding principles to help us build out our feature set:
- Data visibility and Verifiability
- Experimentation
- Responsiveness
- Cross platform
These guiding principles are really what have gone into building out he user experience of the software. Currently, it is a cross platform desktop application, this gets you the ability to run datasets where you need to (even without access to the internet if you’ve been using a cloud based solution).
Data Visibility and Verifiability
If you took a minute to look at the list of what can be done so far, you’ll see that a lot of it has to do with the raw data and the metadata. You need this information at hand to audit the results that you get. We knew that that would be a key part of getting the best results from using the software.
Experimentation
This has mostly to deal with binning of the cycles. We wanted to make it quick and simple to adjust the number of bins or the bin size, and get your results. To do this, the cycles are stored in the database during the extraction phase. This makes it very fast to change your binning strategy. And all of the bins used are stored for additional computation (i.e. Miner’s Rule).
Responsiveness
This is a corollary to our main goal of being efficient. Right off the bat, we knew we didn’t want to lock the users computer up to process this data. Maybe you want to view a previous dataset cycles while importing a new dataset, or you want to start binning previous cycles counted while importing a new dataset, or you want to do all of the above while going through the graph of a previous dataset. All of that can be done, if you build your software in the right way (which was discussed above).
Cross platform
Do you run mac? Do you run windows? Or like me do you run linux? Getting software on the user’s computer is the most important part, with the big 3 platforms it can be challenging to do just that. Go has a great cross platform story and the fyne gui toolkit is a great complement to this. There have been a lot of other great advancements in different language stacks, but I’ve found that go really hits the spot of performance, portability, and tooling that works best for me.
What’s next?
This has been an introduction discussion to the rainflow cycle counting software that we’ve been working on. As you’ve read, this post discusses the basics of what the software is to do, with more detail on the goals in building it.